Probability theory
2008/9 Schools Wikipedia Selection. Related subjects: Mathematics
Probability theory is the branch of mathematics concerned with analysis of random phenomena. The central objects of probability theory are random variables, stochastic processes, and events: mathematical abstractions of non-deterministic events or measured quantities that may either be single occurrences or evolve over time in an apparently random fashion. Although an individual coin toss or the roll of a die is a random event, if repeated many times the sequence of random events will exhibit certain statistical patterns, which can be studied and predicted. Two representative mathematical results describing such patterns are the law of large numbers and the central limit theorem.
As a mathematical foundation for statistics, probability theory is essential to many human activities that involve quantitative analysis of large sets of data. Methods of probability theory also apply to description of complex systems given only partial knowledge of their state, as in statistical mechanics. A great discovery of twentieth century physics was the probabilistic nature of physical phenomena at atomic scales, described in quantum mechanics.
History
The mathematical theory of probability has its roots in attempts to analyse games of chance by Gerolamo Cardano in the sixteenth century, and by Pierre de Fermat and Blaise Pascal in the seventeenth century (for example the " problem of points").
Initially, probability theory mainly considered discrete events, and its methods were mainly combinatorial. Eventually, analytical considerations compelled the incorporation of continuous variables into the theory. This culminated in modern probability theory, the foundations of which were laid by Andrey Nikolaevich Kolmogorov. Kolmogorov combined the notion of sample space, introduced by Richard von Mises, and measure theory and presented his axiom system for probability theory in 1933. Fairly quickly this became the undisputed axiomatic basis for modern probability theory.
Treatment
Most introductions to probability theory treat discrete probability distributions and continuous probability distributions separately. The more mathematically advanced measure theory based treatment of probability covers both the discrete, the continuous, any mix of these two and more.
Discrete probability distributions
Discrete probability theory deals with events that occur in countable sample spaces.
Examples: Throwing dice, experiments with decks of cards, and random walk.
Classical definition: Initially the probability of an event to occur was defined as number of cases favorable for the event, over the number of total outcomes possible in an equiprobable sample space.
For example, if the event is "occurrence of an even number when a die is rolled", the probability is given by 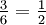 , since 3 faces out of the 6 have even numbers and each face has the same probability of appearing.
, since 3 faces out of the 6 have even numbers and each face has the same probability of appearing.
Modern definition: The modern definition starts with a set called the sample space, which relates to the set of all possible outcomes in classical sense, denoted by 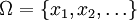 . It is then assumed that for each element
. It is then assumed that for each element 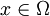 , an intrinsic "probability" value
, an intrinsic "probability" value 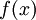 is attached, which satisfies the following properties:
is attached, which satisfies the following properties:
![f(x)\in[0,1]\mbox{ for all }x\in \Omega\,;](../../images/698/69853.png)
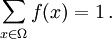
That is, the probability function f(x) lies between zero and one for every value of x in the sample space Ω, and the sum of f(x) over all values x in the sample space Ω is exactly equal to 1. An event is defined as any subset  of the sample space
of the sample space  . The probability of the event defined as
. The probability of the event defined as
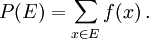
So, the probability of the entire sample space is 1, and the probability of the null event is 0.
The function mapping a point in the sample space to the "probability" value is called a probability mass function abbreviated as pmf. The modern definition does not try to answer how probability mass functions are obtained; instead it builds a theory that assumes their existence.
Continuous probability distributions
Continuous probability theory deals with events that occur in a continuous sample space.
Classical definition: The classical definition breaks down when confronted with the continuous case. See Bertrand's paradox.
Modern definition: If the sample space is the real numbers (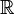 ), then a function called the cumulative distribution function (or cdf)
), then a function called the cumulative distribution function (or cdf) 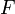 is assumed to exist, which gives
is assumed to exist, which gives 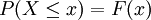 for a random variable X. That is, F(x) returns the probability that X will be less than or equal to x.
for a random variable X. That is, F(x) returns the probability that X will be less than or equal to x.
The cdf must satisfy the following properties.
- is a monotonically non-decreasing, right-continuous function;
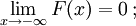
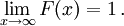
If is differentiable, then the random variable X is said to have a probability density function or pdf or simply density 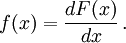
For a set 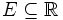 , the probability of the random variable X being in is defined as
, the probability of the random variable X being in is defined as
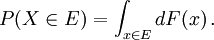
In case the probability density function exists, this can be written as
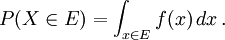
Whereas the pdf exists only for continuous random variables, the cdf exists for all random variables (including discrete random variables) that take values on 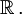
These concepts can be generalized for multidimensional cases on 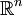 and other continuous sample spaces.
and other continuous sample spaces.
Measure-theoretic probability theory
The raison d'être of the measure-theoretic treatment of probability is that it unifies the discrete and the continuous, and makes the difference a question of which measure is used. Furthermore, it covers distributions that are neither discrete nor continuous nor mixtures of the two.
An example of such distributions could be a mix of discrete and continuous distributions, for example, a random variable which is 0 with probability 1/2, and takes a value from random normal distribution with probability 1/2. It can still be studied to some extent by considering it to have a pdf of ![(\delta[x] + \varphi(x))/2](../../images/698/69866.png) , where δ[x] is the Kronecker delta function.
, where δ[x] is the Kronecker delta function.
Other distributions may not even be a mix, for example, the Cantor distribution has no positive probability for any single point, neither does it have a density. The modern approach to probability theory solves these problems using measure theory to define the probability space:
Given any set Ω, (also called sample space) and a σ-algebra 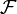 on it, a measure P is called a probability measure if
on it, a measure P is called a probability measure if
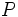 is non-negative;
is non-negative;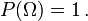
If is a Borel σ-algebra then there is a unique probability measure on for any cdf, and vice versa. The measure corresponding to a cdf is said to be induced by the cdf. This measure coincides with the pmf for discrete variables, and pdf for continuous variables, making the measure-theoretic approach free of fallacies.
The probability of a set in the σ-algebra is defined as
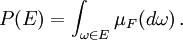
where the integration is with respect to the measure 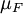 induced by
induced by 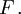
Along with providing better understanding and unification of discrete and continuous probabilities, measure-theoretic treatment also allows us to work on probabilities outside , as in the theory of stochastic processes. For example to study Brownian motion, probability is defined on a space of functions.
Probability distributions
Certain random variables occur very often in probability theory because they well describe many natural or physical processes. Their distributions therefore have gained special importance in probability theory. Some fundamental discrete distributions are the discrete uniform, Bernoulli, binomial, negative binomial, Poisson and geometric distributions. Important continuous distributions include the continuous uniform, normal, exponential, gamma and beta distributions.
Convergence of random variables
In probability theory, there are several notions of convergence for random variables. They are listed below in the order of strength, i.e., any subsequent notion of convergence in the list implies convergence according to all of the preceding notions.
- Convergence in distribution: As the name implies, a sequence of random variables
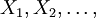 converges to the random variable
converges to the random variable 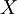 in distribution if their respective cumulative distribution functions
in distribution if their respective cumulative distribution functions 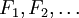 converge to the cumulative distribution function of , wherever is continuous.
converge to the cumulative distribution function of , wherever is continuous.
-
- Most common short hand notation:
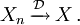
- Most common short hand notation:
- Weak convergence: The sequence of random variables
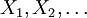 is said to converge towards the random variable weakly if
is said to converge towards the random variable weakly if 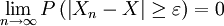 for every ε > 0. Weak convergence is also called convergence in probability.
for every ε > 0. Weak convergence is also called convergence in probability.
-
- Most common short hand notation:
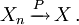
- Most common short hand notation:
- Strong convergence: The sequence of random variables is said to converge towards the random variable strongly if
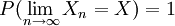 . Strong convergence is also known as almost sure convergence.
. Strong convergence is also known as almost sure convergence.
-
- Most common short hand notation:
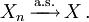
- Most common short hand notation:
Intuitively, strong convergence is a stronger version of the weak convergence, and in both cases the random variables show an increasing correlation with . However, in case of convergence in distribution, the realized values of the random variables do not need to converge, and any possible correlation among them is immaterial.
Law of large numbers
Common intuition suggests that if a fair coin is tossed many times, then roughly half of the time it will turn up heads, and the other half it will turn up tails. Furthermore, the more often the coin is tossed, the more likely it should be that the ratio of the number of heads to the number of tails will approach unity. Modern probability provides a formal version of this intuitive idea, known as the law of large numbers. This law is remarkable because it is nowhere assumed in the foundations of probability theory, but instead emerges out of these foundations as a theorem. Since it links theoretically-derived probabilities to their actual frequency of occurrence in the real world, the law of large numbers is considered as a pillar in the history of statistical theory.
The law of large numbers (LLN) states that the sample average 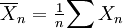 of (independent and identically distributed random variables with finite expectation μ) converges towards the theoretical expectation μ.
of (independent and identically distributed random variables with finite expectation μ) converges towards the theoretical expectation μ.
It is in the different forms of convergence of random variables that separates the weak and the strong law of large numbers
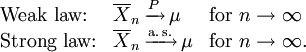
It follows from LLN that if an event of probability p is observed repeatedly during independent experiments, the ratio of the observed frequency of that event to the total number of repetitions converges towards p.
Putting this in terms of random variables and LLN we have 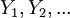 are independent Bernoulli random variables taking values 1 with probability p and 0 with probability 1-p. E(Yi) = p for all i and it follows from LLN that
are independent Bernoulli random variables taking values 1 with probability p and 0 with probability 1-p. E(Yi) = p for all i and it follows from LLN that 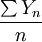 converges to p almost surely.
converges to p almost surely.
Central limit theorem
The central limit theorem explains the ubiquitous occurrence of the normal distribution in nature; it is one of the most celebrated theorems in probability and statistics.
The theorem states that the average of many independent and identically distributed random variables with finite variance tends towards a normal distribution irrespective of the distribution followed by the original random variables. Formally, let be independent random variables with mean 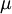 and variance
and variance 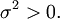 Then the sequence of random variables
Then the sequence of random variables
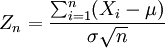
converges in distribution to a standard normal random variable.